I also wrote a proof-of-concept exploit for this vulnerability, demonstrating how it can be used in order to elevate permissions from the context of a regular unprivileged app.
In this blog post, I will cover the technical details of the vulnerability and the exploit. I will start by explaining some background information related to the vulnerability, followed by the details of the vulnerability itself. I will then describe why I chose a particular service as the target for the exploit over other services that are affected by the vulnerability. I will also analyze the service itself in relation to the vulnerability. Lastly, I will cover the details of the exploit I wrote.
Project Treble introduces plenty of changes to how Android operates internally. One massive change is the split of many system services. Previously, services contained both AOSP (Android Open Source Project) and vendor code. After Project Treble, these services were all split into one AOSP service and one or more vendor services, called HAL services. For more background information, the separation between services is described more thoroughly in my BSidesLV talk and in my previous blog post.
The separation of Project Treble introduces an increment in the overall number of IPC (inter-process communication); data which was previously passed in the same process between AOSP and vendor code must now pass through IPC between AOSP and HAL services. As most IPC in Android goes through Binder, Google decided that the new IPC should do so as well.
But simply using the existing Binder code was not enough, Google also decided to perform some modifications. First, they introduced multiple Binder domains in order to separate between this new type of IPC and others. More importantly, they introduced HIDL – a whole new format for the data passed through Binder IPC. This new format is supported by a new set of libraries, and is dedicated to the new Binder domain for IPC between AOSP and HAL services. Other Binder domains still use the old format.
The operation of the new HIDL format compared to the old one is a bit like layers. The underlying layer in both cases is the Binder kernel driver, but the top layer is different. For communication between HAL and AOSP services, the new set of libraries is used; for other types of communication, the old set of libraries is used. Both sets of libraries contain very similar code, to the point that some of the original code was even copied to the new HIDL libraries (although personally I could not find a good reason for copy-pasting code here, which is generally not a good practice). The usage of each of these libraries is not exactly the same (you cannot simply substitute one with another), but it is still very similar.
Both sets of libraries represent data that transfers in Binder transactions as C++ objects. This means that HIDL introduces its own new implementation for many types of objects, from relatively simple ones like objects that represent strings to more complex implementations like file descriptors or references to other services.
One important aspect of Binder IPC is the use of shared memory. In order to maintain simplicity and good performance, Binder limits each transaction to a maximum size of 1MB. For situations where processes wish to share larger amounts of data between each other through Binder, shared memory is used.
In order to share memory through Binder, processes utilize Binder’s feature of sharing file descriptors. The fact that file descriptors can be mapped to memory using mmap allows multiple processes to share the same memory region by sharing a file descriptor. One issue here with regular Linux (non-Android) is that file descriptors are normally backed by files; what if processes want to share anonymous memory regions? For that reason, Android has ashmem, which allows processes to allocate memory to back file descriptors without an actual file involved.
Sharing memory through Binder is an example of different implementations between HIDL and the old set of libraries. In both cases the eventual actions are the same: one process maps an ashmem file descriptor in its memory space, transfers that file descriptor to another process through Binder and then that other process maps it in its own memory space. But the implementations for the objects which handle this are different.
In HIDL’s case, an important object for sharing memory is hidl_memory. As described in the source code: “hidl_memory is a structure that can be used to transfer pieces of shared memory between processes”.
Let’s take a closer look at hidl_memory by looking at its members:
When transferring structures like this through Binder in HIDL, complex objects (like hidl_handle or hidl_string) have their own custom code for writing and reading the data, while simple types (like integers) are transferred “as is”. This means that the size is transferred as a 64 bit integer. On the other hand, in the old set of libraries, a 32 bit integer is used.
This seems rather strange, why should the size of the memory be 64 bit? First of all, why not do the same as in the old set of libraries? But more importantly, how would a 32 bit process handle this? Let’s check this by taking a look at the code which maps a hidl_memory object (for the ashmem type):
Interesting! Nothing about 32 bit processes, and not even a mention that the size is 64 bit.
So what happens here? The type of the length field in mmap’s signature is size_t, which means that its bitness matches the bitness of the process. In 64 bit processes there are no issues, everything is simply 64 bit. In 32 bit processes on the other hand, the size is truncated to 32 bit, so only the lower 32 bits are used.
This means that if a 32 bit process receives a hidl_memory whose size is bigger than UINT32_MAX (0xFFFFFFFF), the actual mapped memory region will be much smaller. For instance, for a hidl_memory with a size of 0x100001000, the size of the memory region will only be 0x1000. In this scenario, if the 32 bit process performs bounds checks based on the hidl_memory size, they will hopelessly fail, as they will falsely indicate that the memory region spans over more than the entire memory space. This is the vulnerability!
We have a vulnerability; let’s now try to find a target. We are looking for a HAL service which meets the following criteria:
One thing you should note is that even though HAL services are supposed to only be accessible by other system services, this is not really the truth. There are a select few HAL services which are in fact accessible by regular unprivileged apps, each for its own reason. Therefore, the last requirement for the target is:
Luckily, there is one HAL service which meets all these requirements: android.hardware.cas, AKA MediaCasService.
CAS stands for Conditional Access System. CAS in itself is mostly out of the scope of this blog post, but in general, it is similar to DRM (so much so that the differences are not always clear). Simplistically, it functions in the same way as DRM – there is encrypted data which needs to be decrypted.
First and foremost, MediaCasService indeed allows apps to decrypt encrypted data. If you read my previous blog post, which dealt with a vulnerability in a service called MediaDrmServer, you might notice that there is a reason for the comparison with DRM. MediaCasService is extremely similar to MediaDrmServer (the service in charge of decrypting DRM media), from its API to the way it operates internally.
A slight change from MediaDrmServer is the terminology: instead of decrypt, the API is called descramble (although they do end up calling it decrypt internally as well).
Let’s take a look at how the descramble method operates (note that I am omitting some minor parts here in order to simplify things):
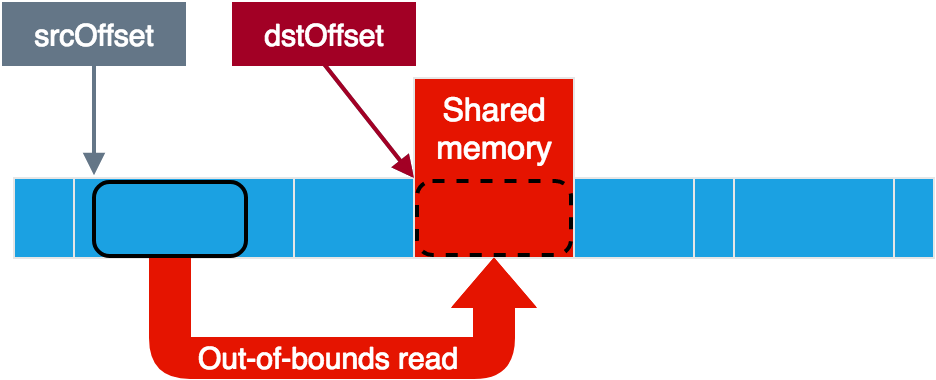
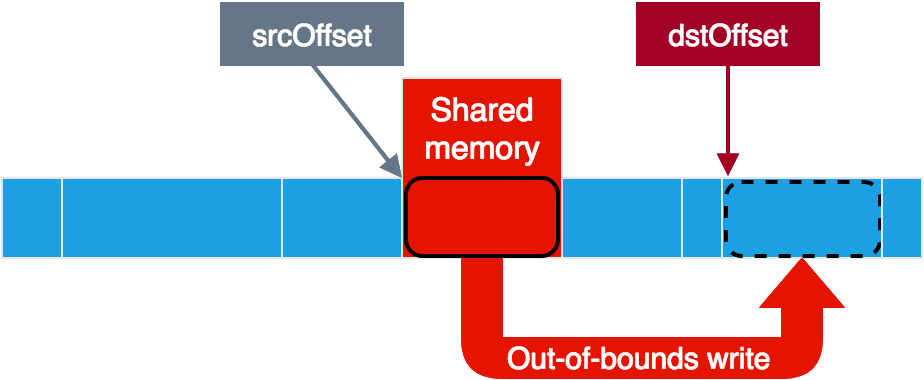
Unsurprisingly, data is shared over shared memory. There is a buffer indicating where the relevant part of the shared memory is (called srcBuffer, but is relevant for both source and destination). On this buffer, there are offsets to where the service reads the source data from and where it writes the destination data to. It is possible to indicate that the source data is in fact clear and not encrypted, in which case the service will simply copy data from source to destination without modifying it.
This looks great for the vulnerability! At least if the service only uses the hidl_memory size in order to verify that it all fits inside the shared memory, and not other parameters. In that case, by letting the service believe that our small memory region spans over its entire memory space, we could circumvent the bounds checks and put the source and destination offsets anywhere we like. This should give us full read+write access to the service memory, as we could read from anywhere to our shared memory and write from our shared memory to anywhere. Note that negative offsets should also work here, as even 0xFFFFFFFF (-1) would be less than the hidl_memory size.
Let’s verify that this is indeed the case by looking at descramble’s code. Quick note: the function validateRangeForSize simply checks that “first_param + second_param <= third_param” while minding possible overflows.
As you can see, the code checks that srcBuffer lies inside the shared memory based on the hidl_memory size. After this the hidl_memory is not used anymore and the rest of the checks are performed against srcBuffer itself. Perfect! All we need then in order to achieve full read+write access is to use the vulnerability and then set srcBuffer’s size to more than 0xFFFFFFFF. This way, any value for the source and destination offsets would be valid.
Before writing an exploit using this (very good) primitive, let’s think about what we really want this exploit to achieve. A look at the SELinux rules for this service shows that it is in fact heavily restricted and does not have a lot of permissions. Still, it has one interesting permission that a regular unprivileged app does not have: access to the TEE (Trusted Execution Environment) device.
This permission is extremely interesting as it lets an attacker access a wide variety of things: different device drivers for different vendors, different TrustZone operating systems and a large amount of trustlets. In my previous blog post, I have already discussed how dangerous this permission can be.
While there are indeed many things you can do with access to the TEE device, at this point I merely wanted to prove that I could get this access. Hence, my objective was to perform a simple operation which requires access to the TEE device. In the Qualcomm TEE device driver, there is a fairly simple ioctl which queries for the version of the QSEOS running on the device. Therefore, my target when building the exploit for MediaCasService was to run this ioctl and get its result.
Note: My exploit is for a specific device and build – Pixel 2 with the May 2018 security update (build fingerprint: “google/walleye/walleye:8.1.0/OPM2.171019.029.B1/4720900:user/release-keys”). A link to the full exploit code is available at the end of the blog post.
So far we have full read+write over the target process memory. While this is a great primitive, there are two issues that need to be solved:
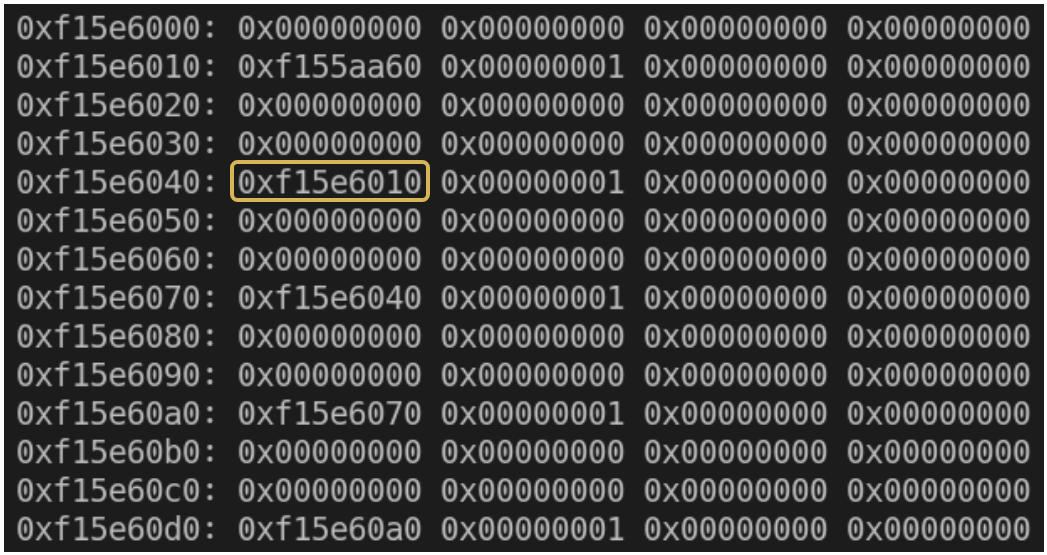
Let’s take a look at some of the memory maps of the linker in the service memory space for this specific build:
Let’s look at the data in the linker_alloc straight after the gap:
So far we solved the second issue, but have only partially solved the first issue. We do have the address of our shared memory, but not of other interesting data. But what other data are we interested in?
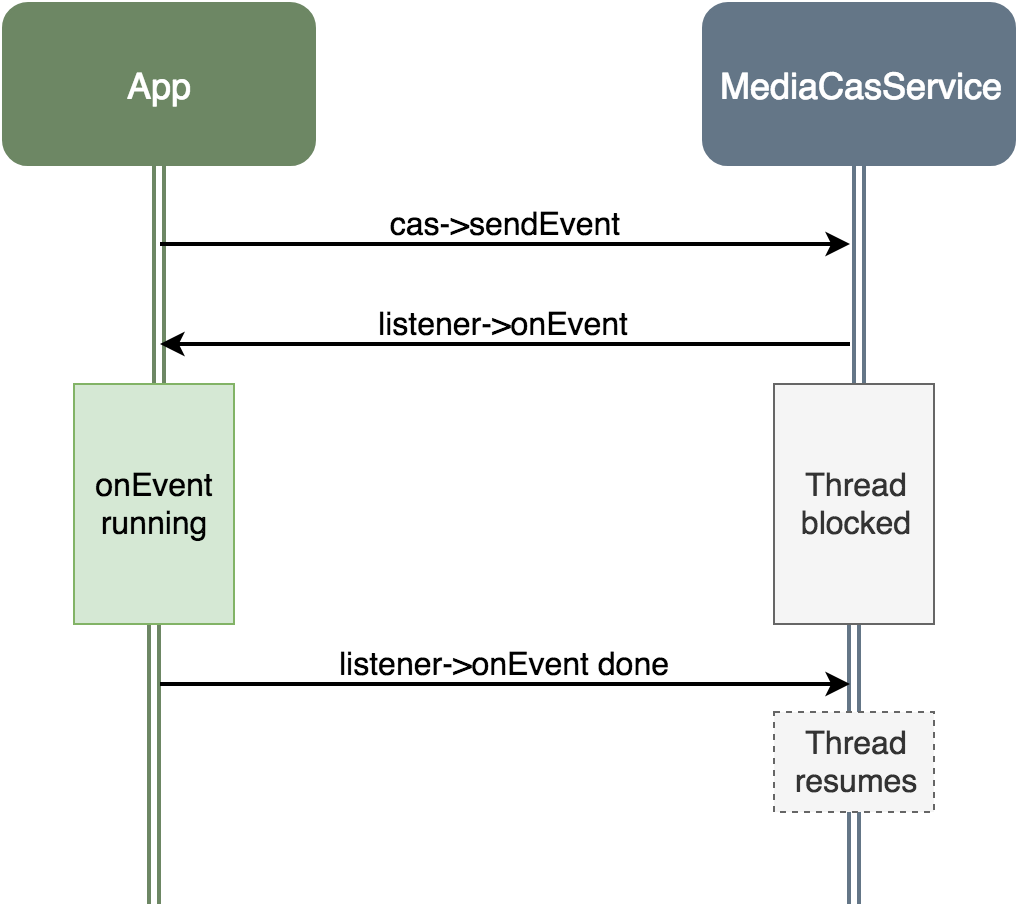
One part of the MediaCasService API is the ability for clients to provide listeners to events. If a client provides a listener, it will be notified when different CAS events occur. A client can also trigger events by its own, which will then be sent back to the listener. The way this works through Binder and HIDL is that when the service sends an event to the listener, it will wait until the listener finished processing the event; a thread will be blocked waiting for the listener.
This is great for us; we can cause a thread in the service to be blocked waiting for us, in a known pre-determined thread. Once we have a thread in this state, we can modify its stack in order to hijack it; then only after we finish, we can resume the thread by finishing to process the event. But how do we find the thread stack in memory?
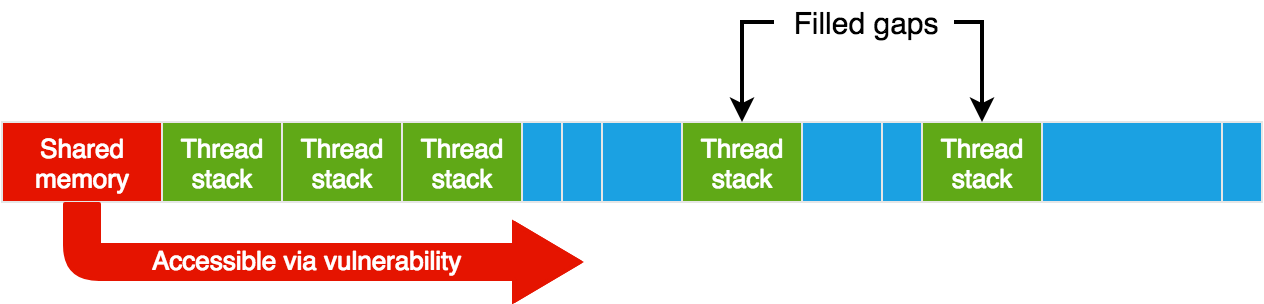
As our deterministic shared memory address is so high, the distance between that address and possible locations of the blocked thread stack is big. The effect of ASLR makes it too unreliable to try to find the thread stack relatively from our deterministic address, so we use another approach. We try to use a bigger shared memory and have it mapped before the blocked thread stack, so we will be able to reach it relatively through the vulnerability.
Instead of only getting one thread to that blocked state, we get multiple (5) threads. This causes more threads to be created, with more thread stacks allocated. By doing this, if there are a few thread-stack-sized gaps in memory, they should be filled, and at least one thread stack in a blocked thread should be mapped at a low address, without any library mapped before it (remember, mmap’s behavior is to map regions at high addresses before low addresses). Then, ideally, if we use a large shared memory, it should be mapped before that.
One drawback is that there is a chance that other unexpected things (like jemalloc heap) will get mapped in the middle, so the blocked thread stack won’t be where we expect it to be. There could be multiple approaches to solve this. I decided to simply crash the service (using the vulnerability in order to write to an unmapped address) and try again, as every time the service crashes it simply restarts. In any case, this scenario normally does not happen, and even when it does, one retry is usually enough.
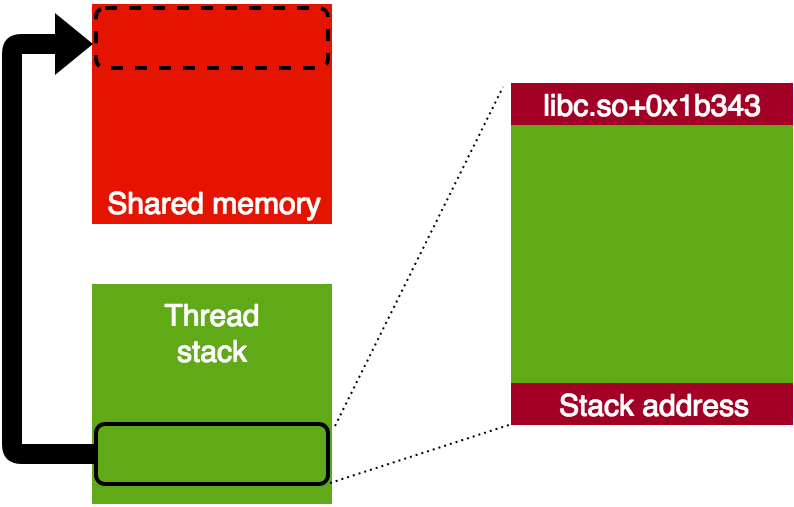
Once our shared memory is mapped before the blocked thread stack, we use the vulnerability to read two things from the thread stack:
From now on, we can read and write to the thread stack using the vulnerability. We have both the address of the deterministic shared memory location and the address of the thread stack, so by using the difference between the addresses we can reach the thread stack from our shared memory (the small one with deterministic location).
We have full access to a blocked thread stack which we can resume, so the next step is to execute a ROP chain. We know exactly which part of the stack to overwrite with our ROP chain, as we know the exact state that the thread is blocked at. After overwriting part of the stack, we can resume the thread so the ROP chain is executed.
Unfortunately, the SELinux limitations on this process prevent us from turning this ROP chain into full arbitrary code execution. There is no execmem permission, so anonymous memory cannot be mapped as executable, and we have no control over file types which can be mapped as executable. In this case, the objective is pretty simple (running a single ioctl), so I simply wrote a ROP chain which does this. In theory, if you want to perform more complex stuff, the primitive is so strong that it should still be possible. For instance, if you want to perform complex logic based on a result of a function, you could perform multi-stage ROP: perform one ROP chain which runs that function and writes its result somewhere, read that result, perform the complex logic in your own process and then run another ROP chain based on that.
As was previously mentioned, the objective is to obtain the QSEOS version. Here is the code that is essentially performed by the ROP chain in order to do that:
Building the ROP chain itself is pretty straightforward. There are enough gadgets in libc to perform it and all the symbols are in libc as well, and we already have libc’s address.
After we are done, the process is left in a bit of an unstable state, as we hijacked a thread to execute our ROP chain. In order to leave everything in a clean state, we simply crash the service using the vulnerability (by writing to an unmapped address) in order to let it restart.
As I previously discussed in my BSidesLV talk and in my previous blog post, Google claims that Project Treble benefits Android security. While that is true in many cases, this vulnerability is another example of how elements of Project Treble could lead to the opposite. This vulnerability is in a library introduced specifically as part of Project Treble, and does not exist in a previous library which does pretty much the same thing. This time, the vulnerability is in a commonly used library, so it affects many high-privileged services.
Full exploit code is available on GitHub. Note: the exploit is only provided for educational or defensive purposes; it is not intended for any malicious or offensive use.
I would like to thank Google for their quick and professional response, Adam Donenfeld (@doadam), Ori Karliner (@oriHCX), Rani Idan (@raniXCH), Ziggy (@z4ziggy) and the rest of the Zimperium zLabs team.
If you have any questions, you are welcome to DM me on Twitter (@tamir_zb).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}